(Whereby I merely document the work done by others, my absolute favorite approach to any problem!)
Well, first of all I guess I need to explain what the hell “Bayesian” means, as it’s a big, weird word and is actually in the title of this post. It’s a statistical approach, named after Thomas Bayes, a mathematician who lived in the 1700s. It’s used in many areas, but I want to write about its use specifically in search operations.
Bayesian search theory has been used for many years in ocean searches, especially by the U.S. Coast Guard. It’s only been in more recent times that computational capabilities have improved and become accessible enough that the technique is being applied to land searches. I’m far from an expert on this (the Ewasko work I’m reporting here WAS done by experts), but I’ll take a stab at explaining the basics. Those readers who know of this stuff will not be discouraged from snickering.
The process is all about creating an optimal search map based on the specifics of the case. Suppose you have a subject who went missing on a hike in a certain area. If the area is bounded by roads or other impassable topographical barriers, it’s then possible to put a firm boundary on the search area, no matter how large it may be. The base assumption here is that there’s a 100% chance the subject is within the established boundaries (theories of foul play or alien abduction notwithstanding).
The next step is to subdivide the search area into equally sized cells. Depending upon the type of search the cells could be as small as 50 meters square for a detailed land search or up to a kilometer square, or more, for an ocean search. But usually the cells are all the same size. Yeah, this could end up being a lot of cells, but what do we care if we have a computer doing the math?
Next, the total probability of 100% is divided by the number of cells to give the average probability of the subject being in any one cell. If you’re dealing with a large number of cells, then that’s a pretty small probability for each one, isn’t it? But here’s where things get interesting.
While all cells start out as being equally sized, they are far from equal. Each cell has a set of attributes, unique to that cell, which can greatly modify the actual probability of the subject being in that cell. And by using each cell’s attributes to adjust its base probability it can provide a more realistic probability of the subject being in that cell.
An example……Consider the distance from any one cell to the subject’s last known point (LKP). The chance that a subject might be in a cell at the very perimeter of the search area is likely much lower than the chance the subject is in a cell much closer to the LKP. So a probability factor can be developed for each cell based upon distance from the LKP. Whether that factor is linear, exponential or even Gaussian (a bell curvy thing) doesn’t matter so much as there IS a factor.
Another example might be a factor allowing for proximity to hiking trails in the search area. Assuming the trails within the search area get reasonable hiker traffic, perhaps the further from a hiking trail, the higher the factor. Or perhaps based upon typical lost person behavior in the search area, maybe the factor would be highest at, say, a mile away from the nearest trail (assuming lost people don’t usually stray much further than that), before it starts dropping off. But an interesting aspect of this factor would be that the assigned probability of any cell directly on a trail would be zero because other hikers on the trail would have come across the missing subject. So some cells can be zeroed out and not require searching.
Depending upon the nature of the search area and the specific circumstances of the case, it’s possible to come up with a number of probability factors for different attributes. These factors can either increase or decrease the likelihood the missing person will be in a particular search cell. In addition to the two factors already mentioned, other possibilities could include terrain steepness, elevation change from the LKP, brush/tree coverage (i.e., visibility), even distance from cell phone coverage zones if the subject was known to have been carrying a cell phone.
Once a SAR analyst is happy with the factors selected, each search cell has its different factors multiplied together to give a total probability factor for that specific cell. Some cells, like those on a well used hiking trail, may end up having probability factors of zero. In any case, that 100 percent probability of the subject being within the search area is now redistributed to all the cells based on their different factor probabilities. If you add up these adjusted probabilities of every cell within the search area, it should total 100%. Granted, the probability of any individual cell again may be quite small, but relatively, they tell the searchers where to look first.
OK, this is kind of obvious, right? Most experienced SAR people can look at a map and based upon their experience know where to look first. But where do you look second, third or even tenth? That’s where this Bayesian stuff starts to rock.
So let’s say the first day of searching has concluded and the subject is still missing. Once the incident command post has all the searchers’ GPS tracks for the day, the search manager can then enter them into a computer and adjust the Bayesian model. In essence, with the searchers having passed through a number of cells and clearing them, it can be said with some certainty that those cells now have a probability of zero. In practice, it’s a bit trickier than that, as a searcher’s Probability of Detection falls off with distance from the centerline of a searcher’s travel. In some cases, the ground may be visible for a hundred feet on each side, and in others perhaps only twenty feet. Ummm…see where a terrain steepness factor might be useful?
So after the first day of searching with this new (and any other) information in hand, the computer rebalances the probabilities for each cell. The accepted search area must still equal 100 percent, but now many cells have had their probabilities diminished or reduced to zero by the searchers passing through them. The probability rebalancing thus raises the probabilities in the remaining cells and tells the searchers where the next best odds are. Lather, rinse and repeat until the subject is found.
So all that blathering is a very rudimentary explanation of how Bayesian techniques can be used in SAR. But what, you ask (and I can hear you asking), does this have to do with Ewasko? Ahem…
Some time ago I was contacted by a GIS specialist by the name of Lorie Velarde (AKA the GIS Queen) with the City of Irvine Police Department who came across my Ewasko postings and thought it might be “fun” to play around with the case from a GIS viewpoint. I cannot explain such inclinations, I can only exploit them. Bayesian techniques, while I understand them and can spell the name, are well above my pay grade. Apparently not so for Lorie and her contacts. So she was interested in tackling the Ewasko incident to see if she could create a mapping of likely spots Ewasko may have ended up.
To this end Lorie enlisted the help of Dr. Kim Rossmo of Texas State University who has used Bayesian techniques for criminology purposes. Dr. Rossmo developed the probability factors involved for this simplified Ewasko model. Taking the factor data, Lorie used ArcGIS to create a little over 300,000, 100-square-foot cells and produced a probability model she was able to export as a kmz file for Google Earth. The area used to apply Bayesian techniques to is shown below.

The assumed boundaries for this Bayesian analysis are shown in dark blue. They follow roads and major discontinuities in terrain. The base assumption is there’s a 100 percent probability (or pretty damn close) that Ewasko is within this area. We just don’t know where. Yet.
Notice I used the term, “simplified Ewasko model”? in this case there were only three probability terms:
• Distance from the 10.6 mile Serin tower cell ping. The further a cell was from the recorded Verizon 10.6 mile distance, the lower its probability factor.
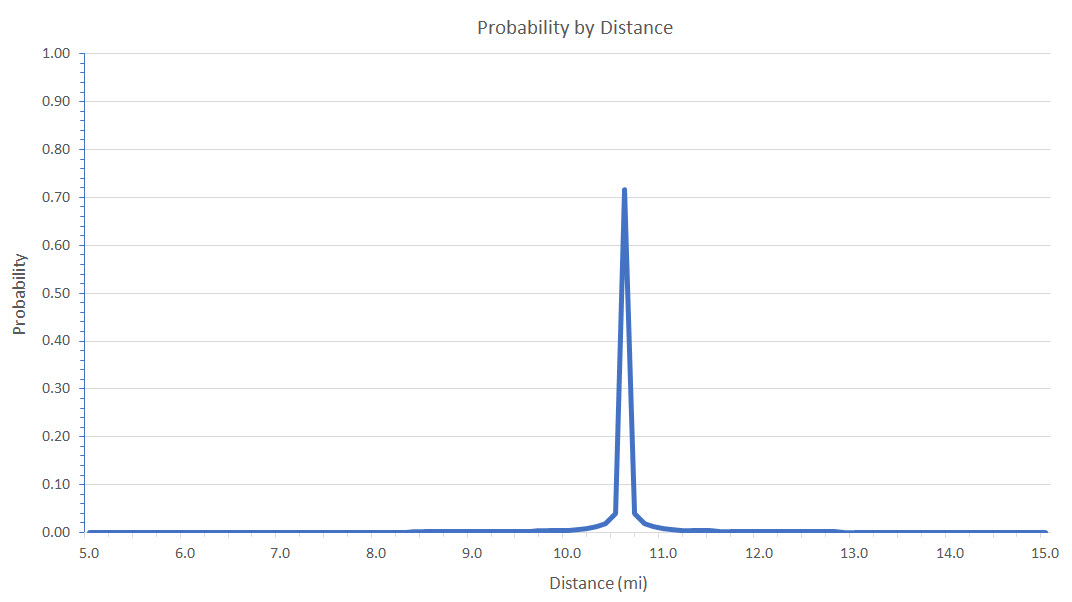
Probabilities used for a cell’s distance from the 10.6 mile Serin cell tower distance. Probabilities were calculated at 0.1 mile intervals using an Excel spreadsheet.
• Whether or not there was cell phone coverage in all or part of a cell. If Verizon cell coverage exists, from an ArcGIS generated splash map of the Serin Tower, covered part of a cell, the probability was adjusted proportionally. The tower was assumed to be 200′ tall (about twice actual), which would show up fringe areas in the splash map.
• If searchers (during the original search or anytime after) passed through all or part of a cell. The factoring assumed a searcher’s line of sight would be good for 50 feet on each side of the recorded GPS track. Anything within this 100 foot swath was assigned a probability of zero. If a search happened up the middle of a 100 foot square cell, the entire cell went to zero. Otherwise the probability was factored proportionally.
Now a few caveats/disclaimers/weaseliness are in order here. The first is while there are a lot of other factors that could have been used, for simplicity and reliability these were selected. They were somewhat championed by moi, and as a result reflect my previously stated prejudices as to what I think are important clues. I’ll freely concede it could be garbage in-garbage out, but if it is, it’s no fault of Lorie or Dr. Rossmo.
Finally, in a traditional Bayesian analysis, the probabilities get readjusted after additional searches take place or new data comes to light. That hasn’t been done here, but rather represents a snapshot in time after the JT88 search of April 19, 2017, and also the portions of the Orbeso/Nguyen search that occurred in potential Ewasko areas in August of 2017 However, future searches could be incorporated into this model and lead to additional adjustments.
So with all that blathering out of the way, below you’ll find a screen grab of Google Earth showing the relative probabilities of unsearched areas You can download the kmz file and play with it yourself in Google Earth by grabbing it from here.

Final probabilities after Bayesian analysis. The redder the higher the probability, bluer the less. Empty areas between spots (cells) may be due to searchers having passed through. The yellow arc is the 10 mile Serin tower radius, blue is 10.6 miles and orange is 11.1 miles.
Is this truly an accurate representation of the best places left to look? Probably (pun intended, of course!) However I’ve spent enough time wandering out in Joshua Tree to retain some skepticism. Also, the model is rather simplistic and could be improved with the additional of more probability factors. But at worse it offers up some new ideas about where to look, and as many know, I’m flat out of ideas. And at best, maybe Bill’s resting in one of the colored squares. Either way, we’re indebted to Lorie and Dr. Rossmo for their work on this and I extend my thanks to them.